Scripting con XML
Es habitual cuando estamos trabajando con consola tener que realizar algún tipo de procesamiento sobre ficheros XML de los cuales queramos extraer cierta información. En consola podemos utilizar dos utilidades para ayudarnos a conseguir este objetivo, xmllint y xlstproc.
Con xmllint podemos comprobar si un fichero XML o HTML está bien formado y cumple con su definición DTD o XSD, aunque la mayoría de las veces utilizaremos otras dos de sus funciones. La principal es la de permitir formatear la salida del XML.
Formatear XML
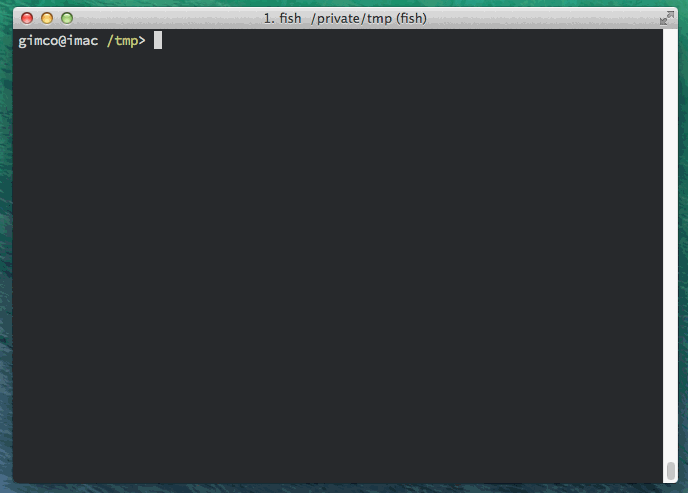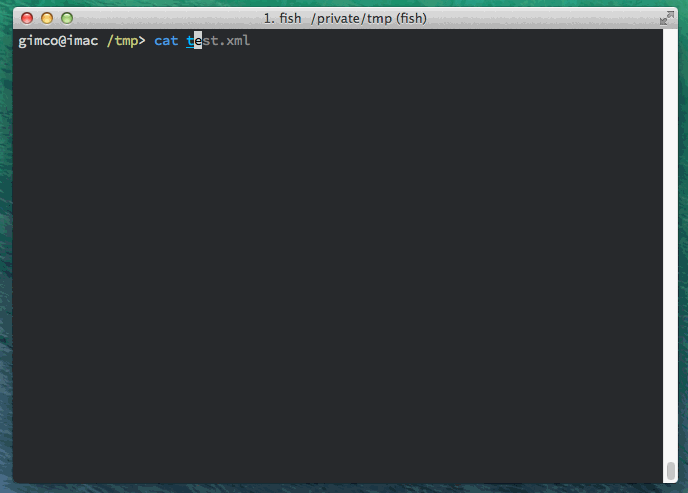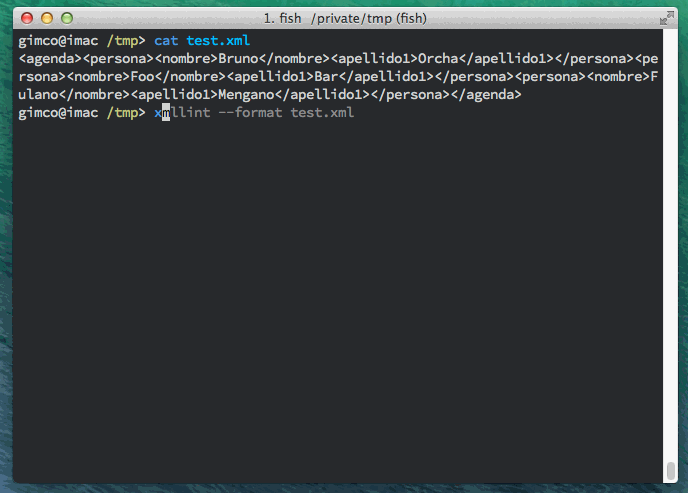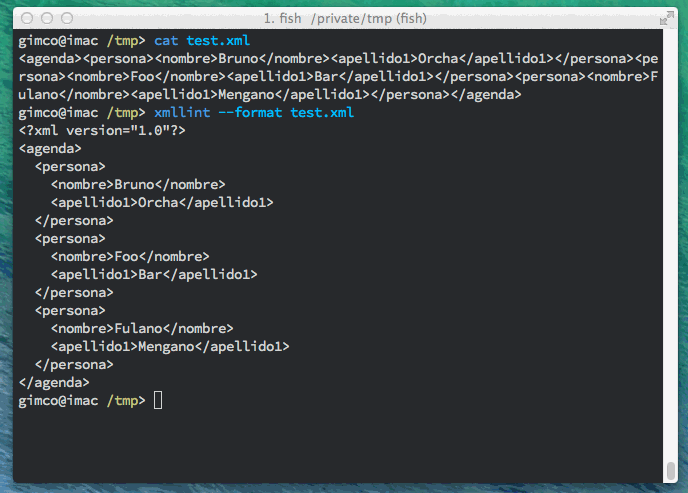
Hay casos en los que nos encontramos con un fichero XML que está condensado o generado para ocupar el mínimo espacio. Para ello se eliminan caracteres opcionales como espacios, tabuladores y saltos de línea. Intentar extraer información de este modo es complejo, por lo que para estos casos se puede utilizar xmllint con el parámetro --format con lo que conseguimos que se muestre de forma mas legible. Por ejemplo, para un fichero test.xml obtendríamos lo siguiente:
gimco@mbair /tmp> cat test.xml
<agenda><persona><nombre>Bruno</nombre><apellido1>Orcha</apellido1></persona><persona><nombre>Foo</nombre><apellido1>Bar</apellido1></persona><persona><nombre>Fulano</nombre><apellido1>Mengano</apellido1></persona></agenda>
Y ahora usando xmllint:
gimco@mbair /tmp> xmllint --format test.xml
<?xml version="1.0"?>
<agenda>
<persona>
<nombre>Bruno</nombre>
<apellido1>Orcha</apellido1>
</persona>
<persona>
<nombre>Foo</nombre>
<apellido1>Bar</apellido1>
</persona>
<persona>
<nombre>Fulano</nombre>
<apellido1>Mengano</apellido1>
</persona>
</agenda>
Una vez formateado el o los ficheros xml que queremos procesar podremos extraer información usando otras utilidades como grep o sed en busca de las zonas del xml que nos interese.
Extrayendo información con XPath
Pero por regla general es mas sencillo utilizar la segunda funcionalidad mas importante de xmllint, que es la capacidad de ejecutar expresiones XPath. XPath vendría a ser el SQL de los ficheros XML, es decir, un lenguaje de expresiones que nos permite filtrar y obtener la información dentro de ficheros XML. De esta forma podemos obtener exactamente el dato que necesitamos dentro de la estructura del fichero. Por ejemplo, del ejemplo anterior, si quisiéramos obtener el nombre de la segunda persona haríamos lo siguiente:
gimco@mbair /tmp> xmllint test.xml --xpath "/agenda/persona[2]/nombre/text()"
Foo
O por ejemplo, supongamos que usamos Redmine como gestor de incidencias, y queremos monitorizar el número de incidencias según un determinado criterio. Puesto que Redmine dispone de una sencilla API Rest podríamos ejecutar la siguiente petición y obtendríamos un xml como el siguiente:
gimco@mbair /tmp> curl http://servidor/redmine/issues.xml?PARAMETROS
<?xml version="1.0" encoding="UTF-8"?><issues type="array" total_count="37" offset="0" limit="25"><issue><id>33085</id><project name="projectA" id="302"/><tracker name="Incidencia" id="4"/><status name="Nueva" id="1"/><priority name="Normal" id="4"/><author name="Foo bar" id="92"/><parent id="33084"/><subject>subject example</subject><description>...</description><start_date>2014-08-20</start_date><due_date></due_date><done_ratio>0</done_ratio><estimated_hours></estimated_hours><created_on>2014-08-20T08:29:50+02:00</created_on><updated_on>2014-08-20T08:29:50+02:00</updated_on></issue><issue><id>33085</id><project name="projectA" id="302"/><tracker name="Incidencia" id="4"/><status name="Nueva" id="1"/><priority name="Normal" id="4"/><author name="Foo bar" id="92"/><parent id="33084"/><subject>subject example</subject><description>...</description><start_date>2014-08-20</start_date><due_date></due_date><done_ratio>0</done_ratio><estimated_hours></estimated_hours><created_on>2014-08-20T08:29:50+02:00</created_on><updated_on>2014-08-20T08:29:50+02:00</updated_on></issue>...</issues>
En este caso vemos que el número total de incidencias está en el atributo total_count de la etiqueta <issues> principal. En nuestro script de monitorización podríamos hacer lo siguiente para obtener este valor:
gimco@mbair /tmp> curl http://servidor/redmine/issues.xml?PARAMETROS | xmllint --xpath "string(/issues/@total_number)" -
37
Otro ejemplo un poco mas complejo. Hace mucho un amigo me preguntó como podía obtener la lista de canciones de un playlist de Spotify, ya que no encontraba ninguna opción, y si seleccionaba todas las canciones, copiaba y pegaba, lo que obtenía eran los identificadores de las canciones, pero no el nombre, el artista y el álbum de éstas.
gimco@mbair /tmp> cat canciones.txt
http://open.spotify.com/track/4oqoEYKWtIcH2ajYm2qQZt
http://open.spotify.com/track/5b88tNINg4Q4nrRbrCXUmg
http://open.spotify.com/track/2JZfTvWWtpaE8NohqRXqFr
http://open.spotify.com/track/7EwISik6EOmK1CZhs68nsg
...
Probablemente en la actualidad existan formas mas sencillas, pero en aquel momento lo solucionamos usando xmllint y la API de Spotify:
gimco@mbair /tmp> cat canciones.txt | while read url; do
curl "http://ws.spotify.com/lookup/1/?uri=spotify:track:${url:30}" | xmllint --xpath "concat(/track/artist/name/text(), ';', /track/name/text(), ';', /track/album/name/text())" - >> lista.csv
done
Tras lo cual ya tendríamos un bonito fichero CSV con el artista, nombre de la canción y álbum.
La última carta, XSLT
Finalmente hay casos en los que necesitamos procesar los ficheros XML con estructuras mas complejas para los que xmllint y sus expresiones XPath se nos quedan cortas. Para estos casos podemos recurrir al lenguaje XSLT para procesar los ficheros XML y extraer de forma mas precisa la información que necesitamos.
Por ejemplo, hace tiempo, por motivos que no recuerdo, cambié de cliente de mensajería del bueno de Pidgin, al jovencito Empathy. Si es verdad que hace bien su trabajo, hay un aspecto que no me gusta en absoluto, y es la parte de buscar en el histórico de conversaciones. El interfaz para buscar conversaciones antiguas no me gusta, además de que funciona bastante regular, por lo que siempre acabo usando grep desde consola cuando quiero buscar en los históricos. El problema viene al revisar los ficheros que usa Empathy para almacenar los logs, ya que los almacena en formato XML y es tedioso seguir la conversación en este formato.
Para solventar esto podemos echar mano de una simple plantilla XSLT que transforme estos ficheros XML en otro formato de salida distintos, como puede ser HTML o un simple texto claro para poder leerlo mas cómodamente. En este caso nos encontramos con ficheros con el siguiente formato:
gimco@mbair /tmp> xmllint --format ~/.local/share/TpLogger/logs/gabble_jabber_myusername_40server0/username@server/20140516.log
<?xml version='1.0' encoding='utf-8'?>
<log>
<message time='20140516T08:10:53' id='myusername@server' name='Bruno' token='' isuser='true' type='normal' message-token='d3f5492e-de50-4124-b6f3-e9cc274353a7'>Go breakfast!</message>
<message time='20140516T08:11:10' id='myfriend@server' name='Javier' token='' isuser='false' type='normal' message-token='d71e4990-1f64-4ea1-9412-6613f6117435'>Baño</message>
...
Como podemos ver, los datos interesantes son el alias del usuario que escribe el mensaje, y el mensaje en sí. La siguiente plantilla generaría un fichero HTML con la conversación:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xml:space="default" version="1.0">
<xsl:template match="/">
<html>
<body>
<xsl:apply-templates match="/log"/>
</body>
</html>
</xsl:template>
<xsl:template match="message">
<p>
<b><xsl:value-of select="@name"/>: </b>
<span>
<xsl:value-of select="text()"/>
</span>
</p>
</xsl:template>
</xsl:stylesheet>
Así que aplicando la plantilla anterior usando xsltproc obtendríamos la conversación en formato HTML:
gimco@mbair /tmp> xsltproc empathy-log.xslt 20140516.log
<html>
<body>
<p><b>Bruno: </b><span>Go breakfast!</span></p>
<p><b>Javier: </b><span>Baño</span></p>
</body>
</html>
Por último, un ejemplo de hace un tiempo cuando tuvimos que analizar qué versiones de una librería Java interna usaban los distintos proyectos de la empresa. Puesto que todos los proyectos usaban maven y cada proyecto tenía su propio repositorio subversion, el primer paso fue crear un script que obtuviera de todos estos repositorios los ficheros pom.xml donde están definidas las dependencias de librerías. Con un poco de scripting y creando una plantilla XSLT conseguimos extraer los datos identificativos (groupId, artifactId y version) de todas las librerías usadas por todos los proyectos en un único fichero CSV.
Los ficheros pom.xml declaran sus dependencias utilizando la etiqueta <dependency> que puede aparecer en distintos lugares del fichero pom.xml. Un ejemplo podría ser:
<?xml version="1.0"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>es.gimco.example</groupId>
<artifactId>mail-smime</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
...
</build>
<dependencies>
<dependency>
<groupId>org.bouncycastle</groupId>
<artifactId>bcmail-jdk14</artifactId>
<version>1.47</version>
</dependency>
<dependency>
<groupId>javax.mail</groupId>
<artifactId>mailapi</artifactId>
<version>1.4.3</version>
</dependency>
<dependency>
<groupId>org.jasypt</groupId>
<artifactId>jasypt</artifactId>
<version>1.9.2</version>
</dependency>
</dependencies>
</project>
Estamos interesados en el contenidos de las etiquetas <groupId>, <artifactId> y <version>. Los fichero CSV son simples archivos de texto que separan los datos por filas y las columnas utilizando algún carácter separador, por ejemplo el ;. A continuación la transformación que buscaría las dependencias y las mostraría en formato CSV:
<?xml version="1.0"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:pom="http://maven.apache.org/POM/4.0.0" xml:space="default" version="1.0">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="//pom:dependency"><xsl:value-of select="pom:groupId/text()"/>;<xsl:value-of select="pom:artifactId/text()"/>;<xsl:value-of select="pom:version/text()"/>;
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
La ejecución de la transformación en este ejemplo daría:
gimco@mbair /tmp> xlstproc deps.xslt pom.xml
org.bouncycastle;bcmail-jdk14;1.47;
javax.mail;mailapi;1.4.3;
org.jasypt;jasypt;1.9.2;
Por último, el script que buscaría en todos los repositorios subversion por ficheros pom.xml. Para cada fichero encontrado, extraería las dependencias anteriores, para finalmente agregar algunas columnas extras, como en repositorio y el fichero del que provienen las dependencias.
#En cada repositorio buscamos los ficheros pom.xml descartando los que estén en la carpeta /tags/ y concatenamos al fichero de salida las dependencias encontradas.
echo "Repositorio;Pom;groupId;artifactId;version" > versiones.csv
for repo in REPOS_PATH/* ; do
svn ls -R file:///REPOS_PATH/$repo | grep -ev "/tags/" | grep pom.xml | while read pom ; do
svn cat file:///PATH/$repo/$pom | xsltproc deps.xslt - | while read deps; do
echo -n "$repo;$pom;$deps" >> versiones.csv
done
done
done
Conclusiones
Para poder extraer información de forma sencilla de ficheros XML es necesario conocer XPath y XSLT, que son las tecnologías naturales para tratar con este formato de datos. En el caso de linux tenemos los comandos xmllint y xlstproc que nos permite formatear, buscar datos simples y por último y mas potente, aplicar transformaciones a los xml para obtener lo que nos interesa.
