ANTLR
La asignatura de Compiladores en la Universidad fue la más intensa y extenuante con diferencia. Era una asignatura que condensaba una materia teórica amplia y densa en muy corto espacio de tiempo, donde romábamos apuntes a una velocidad endiablada, éramos aprendices de taquígrafos, fotocopiadores de pizarras. No en vano llamábamos a nuestra profesora Turbotere. Nuestra única salvación era acudir al legendario libro del dragón rojo para poder encajar todas las piezas y entender lo que estábamos haciendo. Fue mi primer contacto con las gramáticas, analizadores léxico-sintácticos y la utilización de las herramientas lex/flex/yacc/bison.

La segunda incursión fue mas satisfactoria con la utilización de ANTLR y la creación de un compilador para un lenguaje de programación pseudocódigo inventado. Ver que puedes programar usando un lenguaje que tú mismo has diseñado y que después puedes compilarlo y ejecutarlo como cualquier otro lenguaje es inspirador.
Aunque este tipo de herramientas son muy poderosas pertenecen una rama de la informática poco habitual para la gran mayoría de desarrolladores de aplicaciones web.
Refactorización
Durante la migración de una aplicación legacy con mas de dos décadas a sus espaldas y programada en el lenguaje de programación Natural de Software AG (un lenguaje similar a COBOL) tuve la oportunidad de volver a utilizar algunas de estas herramientas. Si bien, uno no de los primeros consejos cuando intentamos integrarnos o sustituir estos sistemas legacy es “don’t feed the monster” (implementar nuevo código en el sistema antiguo debería ser la última de nuestras opciones), mediante la creación de un parseador en ANTLR para el lenguaje NATURAL, pudimos analizar miles y miles de ficheros de código fuente y obtener información muy valiosa y precisa.
Por ejemplo, pudimos analizar las dependencias del sistema, obteniendo así un grafo de todas las llamadas e importaciones desde el módulo principal a los distintos módulos y librerías. Gracias a esto pudimos conseguir un listado exacto de los objetos realmente utilizados por la aplicación, pudiendo descartar centenares de subprogramas obsoletos que ya no se utilizaban (no eran invocados por nadie).
El entorno de desarrollo disponible para interactuar con este sistema es bastante arcaico, siendo la única herramienta disponible un simple buscar y reemplazar (y nada de expresiones regulares por supuesto).
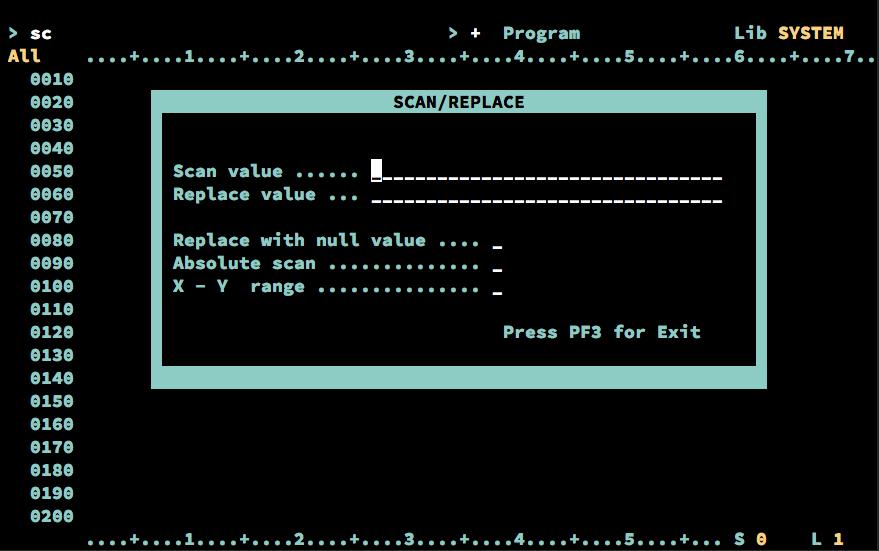
Ya que con el parseador somos capaces de “entender” el código fuente, pudimos realizar refactorizaciones de código precisas de forma automática de distintas partes de la aplicación, pudiendo agregar por ejemplo llamadas de auditoria y notificación de eventos en las operaciones de modificación de base de datos por ejemplo.
Analizando la definición de los ficheros en la base de datos ADABAS que se utilizaba, creamos herramientas que generaban el código SQL DDL, triggers y PL/SQL necesario para exportar, replicar o sincronizar de forma bidireccional los datos en una base de datos Oracle con ADABAS.
Ejemplo
Históricamente Java ha sido un lenguaje poco conciso (la inclusión de var, y lambdas en las últimas versiones han ido mejorando esto): creación de getters y setters, definición de logs en cada clase, métodos toString y equals, llamadas a los métodos close/dispose, etc. Lombok es una librería capaz de enriquecer el código java y evitar tanto código denso y repetitivo. Una de las anotaciones mas útiles de Lombok es @Data que usado en nuestros beans nos evita tener que crear los getters, setters y métodos toString y hashCode.
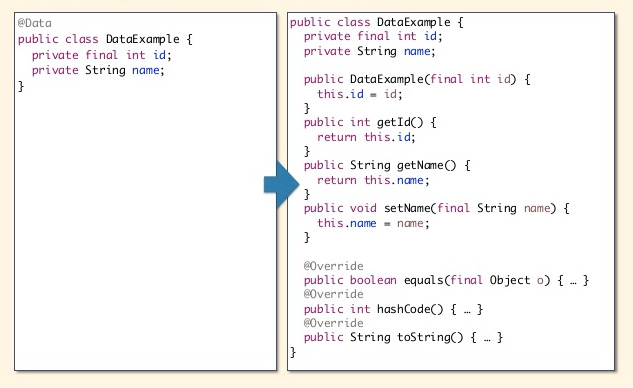
Veamos un ejemplo de como crear una pequeña utilidad de refactorización que elimine todos los métodos de una clase y agregue la anotación @Data usando ANTLR. Para este ejemplo creamos un simple proyecto java, nos descargamos la librería de ANTLR y una de las gramáticas de java de ejemplo. Procesamos con ANTLR las gramáticas para generar los ficheros necesarios para interactuar con nuestro parseador:
$ cd src
$ ls
JavaLexer.g4
JavaParser.g4
$ java -jar ../antlr-4.7.1-complete.jar JavaLexer.g4
$ java -jar ../antlr-4.7.1-complete.jar JavaParser.g4
$ ls
JavaLexer.g4
JavaLexer.interp
JavaLexer.java
JavaLexer.tokens
JavaParser.g4
JavaParser.interp
JavaParser.java
JavaParser.tokens
JavaParserBaseListener.java
JavaParserListener.java
Una vez generados (y compilados) estos ficheros podríamos ver los tokens que son interpretados por el analizador o ver gráficamente el árbol sintáctico de algún fichero de entrada:
$ java -cp ../antlr-4.7.1-complete.jar:../bin org.antlr.v4.gui.TestRig \
Java compilationUnit -tokens Persona.java
[@0,0:5='import',<'import'>,1:0]
[@1,6:6=' ',<WS>,channel=1,1:6]
[@2,7:10='java',<IDENTIFIER>,1:7]
[@3,11:11='.',<'.'>,1:11]
[@4,12:15='util',<IDENTIFIER>,1:12]
[@5,16:16='.',<'.'>,1:16]
[@6,17:20='Date',<IDENTIFIER>,1:17]
[@7,21:21=';',<';'>,1:21]
[@8,22:23='\n\n',<WS>,channel=1,1:22]
[@9,24:29='public',<'public'>,3:0]
...
Creando nuestras herramientas
Crearemos una clase listener capaz de recibir los eventos producidos por el parseador tanto a la hora de comenzar la ejecución de una regla como al terminar una regla. Utilizaremos un objeto de tipo TokenStreamRewriter que es el que nos permite realizar operaciones de inserción, modificación o borrado de tokens con los cambios que queremos en el fichero de salida.
public class LombokDataDomainRefactor extends JavaParserBaseListener {
private TokenStreamRewriter rewriter;
public LombokDataDomainRefactor(CommonTokenStream tokens) {
this.rewriter = new TokenStreamRewriter(tokens);
}
public static void main(String[] args) throws IOException {
}
}
En primer lugar crearemos un analizador léxico para nuestro fichero java de entrada, que puede ser cualquier clase Java Bean. Con este analizador léxico obtendremos un stream de tokens, los mismos que vimos con el ejemplo anterior al utilizar la utilidad TestRig.
Seguidamente crearemos un analizar sintáctico para este stream de tokens, y obtendremos el árbol sintáctico utilizando la regla principal de nuestra gramática, en este caso compilationUnit.
Por último recorreremos este árbol parseado usando nuestro listener, que recibirá los eventos sobre la entrada y salida de las distintas reglas de la gramática:
public static void main(String[] args) throws IOException {
String unit = "src/Persona.java";
JavaLexer lexer = new JavaLexer(CharStreams.fromFileName(unit));
CommonTokenStream tokens = new CommonTokenStream(lexer);
JavaParser parser = new JavaParser(tokens);
ParseTree tree = parser.compilationUnit();
ParseTreeWalker walker = new ParseTreeWalker();
LombokDataDomainRefactor listener = new LombokDataDomainRefactor(tokens);
walker.walk(listener, tree);
String rewrite = listener.rewriter.getText();
FileOutputStream fos = new FileOutputStream(unit);
fos.write(rewrite.getBytes());
fos.close();
}
Es el momento de realizar las operaciones. Cuando entremos en la regla de declaración de un método (methodDeclaration), utilizaremos nuestro reescritor de tokens, y eliminaremos todos los tokens que lo componen:
@Override
public void enterMethodDeclaration(JavaParser.MethodDeclarationContext ctx) {
JavaParser.ClassBodyDeclarationContext parent = (JavaParser.ClassBodyDeclarationContext) ctx.parent.parent;
rewriter.delete(parent.start, parent.stop);
}
Por último, agregamos la línea del import y la anotación @Data justo antes del comienzo de declaración de la clase (regla typeDeclaration)
@Override
public void enterCompilationUnit(JavaParser.CompilationUnitContext ctx) {
JavaParser.TypeDeclarationContext typeDeclaration = ctx.typeDeclaration(0);
rewriter.insertBefore(typeDeclaration.start, "import lombok.Data;\n\n@Data\n");
}
Conclusiones
ANTLR es una herramienta muy potente aunque de muy bajo nivel. Conocer este tipo de herramientas puede hacer que determinados problemas que parecen imposibles e inabarcables se conviertan en algo relativamente sencillo. Crear la gramática para el lenguage Natural requirió superar varias dificultades como la utilización de Island Grammars, Lexical Modes, keywords as identifiers o la inyección de tokens virtuales (END ALL).
Por último, otra de las opciones (aunque inacabadas) fue la posibilidad de utilizar Xtext. Xtext es un framework que nos permite desarrollar nuestro propios lenguajes de programación y DSL que funcionen bajo la JVM. Pero en lugar de limitarse a generar el parseador, es capaz de generar los plugins necesarios para los IDE Eclipse y IntelliJ. Usando Xtext seríamos capaz de crear nuestro propio editor inteligente con colores para la sintaxis, control de errores, navegación entre ficheros/métodos, auto completar, refactorizar, etc. además de que nuestro nuevo lenguaje podría convivir dentro de cualquier proyecto Java, tal y como ocurre con Groovy, Scala o Clojure. Desde luego una opción muy interesante para dotar de nueva vida a lenguajes y sistemas legacy con décadas a sus espaldas.
